AI-Native Threat Modeling
When I ask hiring managers why they’re opening a product security role, the answer is usually the same: we can’t keep up. Development org grew, product surface expanded, and the security team is the bottleneck. It’s not a problem unique to any one organization — it’s the default state of product security. AI-accelerated development and vibe coding are making it worse: more code, shipped faster, with the same security team trying to keep up. The conventional wisdom is that vibe coding is a killer for AppSec — and on the current trajectory, it is.
In this post, I argue that linear scaling won’t solve that problem, and make the case that AI-generated code, treated the right way, can be a force multiplier for security.
1. The AppSec Scaling Problem
The 1:100 ratio — one AppSec engineer for every hundred developers — is the number the industry has quietly accepted as roughly accurate for mature organizations. It sounds manageable until you sit with what it means in practice: a team of five reviewing the output of five hundred, under sprint pressure, across a surface that keeps growing. It’s a demanding job — I wrote about what it actually takes.
The standard response is to hire more security engineers. That’s reasonable when the ratio is temporarily out of balance, but it doesn’t address the structural problem. If the development org doubled and the security team grew from five to ten, you’re at the same ratio. And the ratio assumes a roughly stable development velocity. AI coding assistants are shattering that assumption.
Developers using GitHub Copilot, Cursor, or Claude Code ship more, faster. Vibe coding — letting the model write code from a high-level natural language prompt — compresses timelines further. Features that took two weeks take days. The code surface is expanding at a rate that’s no longer proportional to engineering headcount, which means the AppSec scaling problem is now a two-sided function: development velocity increasing, security team capacity roughly flat. The gap is structural, and it is getting wider.
2. Where Traditional Approaches Break Down
The vocabulary for addressing the AppSec scaling problem is well developed: shift-left, secure-by-design, developer enablement, creating paved roads. They’re not wrong ideas. The problem is that they all require the same scarce resource: AppSec time.
Threat modeling — the recommended practice for high-risk features — is the clearest example. The canonical process: the development team writes a design document; the security team (or a joint session) works through the STRIDE framework or similar, maps data flows and trust boundaries, produces a model; there’s back-and-forth and eventual sign-off. This is genuinely valuable when it happens. In practice, it often doesn’t — the process is time-consuming, and AppSec time is scarce.
What actually happens is one of three failure modes:
- Delay — security reviews become release blockers, friction accumulates, relationships with engineering teams deteriorate.
- Risk-accept — features ship with “accepted risk” security exceptions that go into a backlog and are rarely revisited.
- No review at all — code ships without security involvement, entire product areas built and deployed without the security team ever being in the loop.
With AI now compressing time-to-exploitation — public vulnerabilities can have working proof-of-concept code within hours — the third option is no longer a viable gamble.
Security code reviews have the same structural problem one step later: someone writes code, another team reads it, back-and-forth, sign-off. Every handoff is a scheduling dependency that adds release latency.
3. The Threat Model Maintenance Problem
There’s a second-order problem with threat modeling that gets less attention than the initial production cost: drift.
A threat model is created as a snapshot, but the system keeps evolving. New endpoints added, authentication flows refactored. Six months after a threat model is signed off, it describes a system that no longer looks the same. The question of who owns maintenance is usually a gray area: the development team didn’t write the model and isn’t trained to maintain it; the security team is not aware of changes and has to context-switch back into a system they last looked at months ago. Neither path works well in practice.
Most organizations treat the threat model as a gate the security team required at feature launch — it was produced, the box was checked, and maintenance was never part of the contract. It documents what the system looked like at one point in time and then quietly expires.
4. The Key Insight
Here’s where the mental model needs to shift.
In the current workflow, threat modeling is derivative work: a security person reads what a developer built and reconstructs the security-relevant picture from it — after the fact, inherently lossy, potentially inaccurate, and always one step behind.
Open-source projects such as Tachi and several commercial offerings recognize this and offer tools that automate the reconstruction: read the codebase, analyze diffs, apply a methodology, output a structured model. These tools are useful, but they’re still doing the same derivative work, just faster — reverse-engineering security structure from existing code rather than having a human do it. There’s also a cost dimension: analyzing an existing codebase means feeding it back through an LLM as new input, which is expensive at scale. The larger and more frequently updated the codebase, the higher the token cost of each analysis pass.
Now consider what changes when AI is writing the code — through vibe coding, spec-driven development, AI-generated scaffolding from a design document, or an agentic coding loop that implements a full feature end-to-end.
It doesn’t reverse-engineer anything — it knows, because it built it: every data flow it designed, every entry point it created, every asset it touched, every trust boundary it crossed or established, every authentication decision it made. The complete map required for a threat model exists as a natural byproduct of the design work the AI just did — and it exists at the moment of creation, not after. And because that context is already in the model’s working window, generating the threat model alongside the code is parallel effort on the same inputs, with little additional token cost.
The consequence of this observation is straightforward: threat models should be generated alongside code, as first-class artifacts, not assembled later as derivative documents.
gantt
title 1. Current — human-driven, sequential
dateFormat YYYY-MM-DD
axisFormat %d
section Developer
Design doc :a1, 2024-01-01, 3d
Write code :a2, 2024-01-04, 3d
section Reconstruct (Security)
Reconstruct & model :a3, 2024-01-07, 3d
section Review (Security)
Review & sign-off :a4, 2024-01-10, 2d
gantt
title 2. AI-assisted — LLM writes code, LLM reads code
dateFormat YYYY-MM-DD
axisFormat %d
section Developer
Generate code :b1, 2024-01-01, 3d
section Reconstruct (AI-assisted)
LLM reconstructs TM :b2, 2024-01-04, 2d
section Review (Security)
Review & sign-off :b3, 2024-01-06, 2d
section Time saved
time saved :done, 2024-01-08, 4d
gantt
title 3. AI-native — code and threat model in parallel
dateFormat YYYY-MM-DD
axisFormat %d
section Code
Generate code :c1, 2024-01-01, 3d
section Threat Model
Generate threat model :c2, 2024-01-01, 3d
section Review (Security)
Review & sign-off :c3, 2024-01-04, 2d
section Time saved
time saved :done, 2024-01-06, 6d
Accuracy improves — the model is a direct output from the entity that designed the system, not a reconstruction. Maintenance improves because every code change can regenerate or update it in the same operation; the entity making the change already knows what changed and why. The multi-step, multi-team back-and-forth collapses into a single step. Security practitioners remain in the loop — for methodology, formal sign-off, challenging assumptions the AI didn’t surface — but the labor-intensive baseline work of constructing the model moves from a human bottleneck to an automatic output.
This is what “shift-left” should actually mean: not have the security team review earlier, but produce the security model at the same moment the system is designed. The security artifact is contemporaneous with the code, not chasing it.
5. On Model Bias in Security Analysis
A legitimate concern about this approach is AI model bias. There’s a well-documented pattern in AI-assisted security review: when a model writes code and is then asked to evaluate it for security in the same context window, it tends to anchor to its own design decisions, finding reasons why its choices are sound rather than challenging them. An independent reviewer operating from a fresh context — a second model, or a human who didn’t write the code — is more likely to surface issues the original author missed. This is a real limitation, and it applies directly to using AI for code security review.
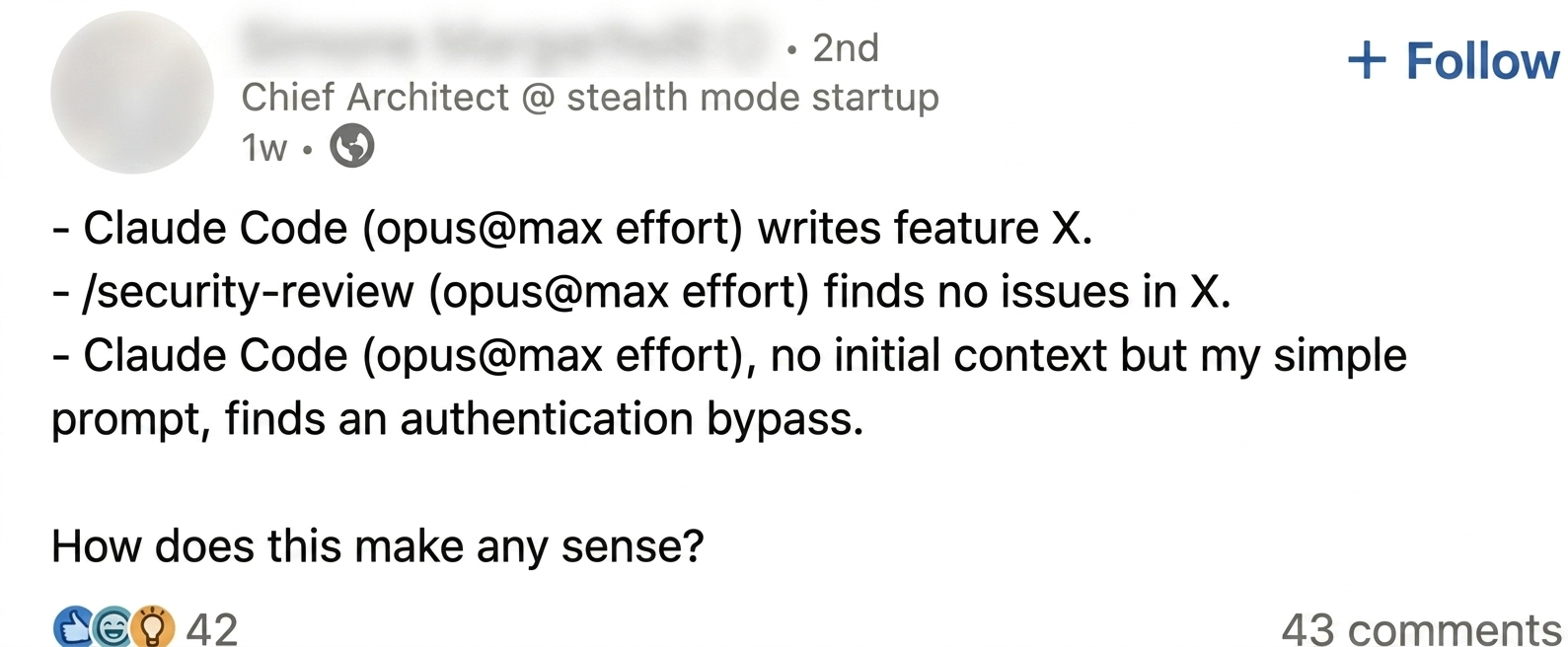
The core distinction here is that code security review and threat modeling are quite different. A security review asks the model to evaluate whether its own implementation is correct and secure — the question where anchoring bites hardest, because the model is judging choices it already committed to. A threat model asks something structurally different: document the architecture, establish trust boundaries, map data flows and assets, then apply a framework like STRIDE that poses a fixed set of questions across threat categories. The framework is external to the code; its questions don’t change based on how well or poorly the implementation is written. The question it asks — given what this system does, what can go wrong in each of these categories? — is answered from the architectural map, not from a judgment about implementation quality.
What bias could still affect is the model’s assessment of severity — an AI that made a particular design trade-off might rate the resulting risk lower than an independent reviewer would. That’s a real concern, and it’s exactly why human review of the model’s outputs and assumptions is still valuable in this workflow.
6. Why Threat Modeling Still Matters
A reasonable objection at this point: if AI writes the code, why not just ask it to write secure code and skip the threat model entirely? We should absolutely ask for that — but threat modeling serves purposes that “write secure code” doesn’t address.
Security architecture documentation. Threat models capture architectural decisions and their security implications: trust boundaries, data classifications, what the system assumes about its environment, where the blast radius of a failure ends. These don’t live in code. A system can be implemented correctly while making architectural trade-offs that accept certain risks; those trade-offs need to be explicit, owned, and findable.
Known gaps and accepted risks. Every system ships with tradeoffs — incomplete defenses, deferred work, risks that were evaluated and accepted. A threat model makes these explicit: here is what we considered, here is what we’re not defending against, and here is why. This matters for accountability, for prioritization, and for the engineer who joins the team six months from now.
Compensating controls. Good security architecture is layered. WAF rules, rate limiting, network segmentation, monitoring and alerting — these don’t live in application code, but they’re part of the security posture. The threat model is where they’re connected to the threats they compensate for. This is also where code-analysis-based automated tools tend to generate false positives: they see the change in isolation, unaware of the external controls that already mitigate a given risk.
Compliance requirements. SOC 2, PCI-DSS, ISO 27001, HIPAA, and similar frameworks require documented evidence of threat analysis. Auditors want artifacts. A threat model that exists and is demonstrably current — generated from the same codebase it describes — is a far stronger compliance artifact than one that was carefully written at launch and hasn’t been touched since.
Incident response preparation. When something goes wrong — and eventually something does — a current threat model tells you what’s at risk, what attacker paths exist, and what to prioritize. You want this analysis done before the incident, not during it.
Stakeholder communication. Engineering leadership, legal, product, and board-level security committees need to understand risk in terms they can act on. The codebase doesn’t serve this purpose; a structured threat model does.
The case for threat modeling doesn’t weaken when AI writes the code — if anything, AI makes the security artifacts cheaper to produce, easier to keep current, and more consistently complete than the human-driven alternative.
Final thoughts
I think this is the direction the AI coding toolchain is already moving toward, even if the full vision hasn’t arrived yet. AI coding tools are increasingly integrating security into the development workflow: GitHub Copilot’s real-time vulnerability detection during code generation, Claude Code’s security analysis during code review, Replit’s Security Agent in the development environment. None of these offer AI-native threat model generation, but they signal that the industry is treating security as something the coding tool prioritizes and produces alongside code. The extension of that to living, maintained threat models is the logical next step.
The reframe for ProdSec practitioners is this: stop thinking of threat modeling as a process your team performs on code that developers write. Start thinking of it as an artifact the AI coding assistant produces alongside the code, which your team validates, challenges, and signs off on. The security team’s job shifts from construction to judgment — which is where human expertise actually compounds.
The dreaded 1:100 ratio won’t disappear. But the work of constructing and maintaining the threat model doesn’t have to stay a human-hours problem. The needle can move — but only if the security team’s role evolves with it.
